
January 5, 2026
In the traditional cybersecurity world, we worry about viruses infecting our software. In the world of 2026 AI security, we worry about "thoughts" infecting our models. Unlike a standard hack that crashes a system, Data and Model Poisoning is a "long-game" attack. It’s subtle, silent, and can stay dormant for months before being triggered.
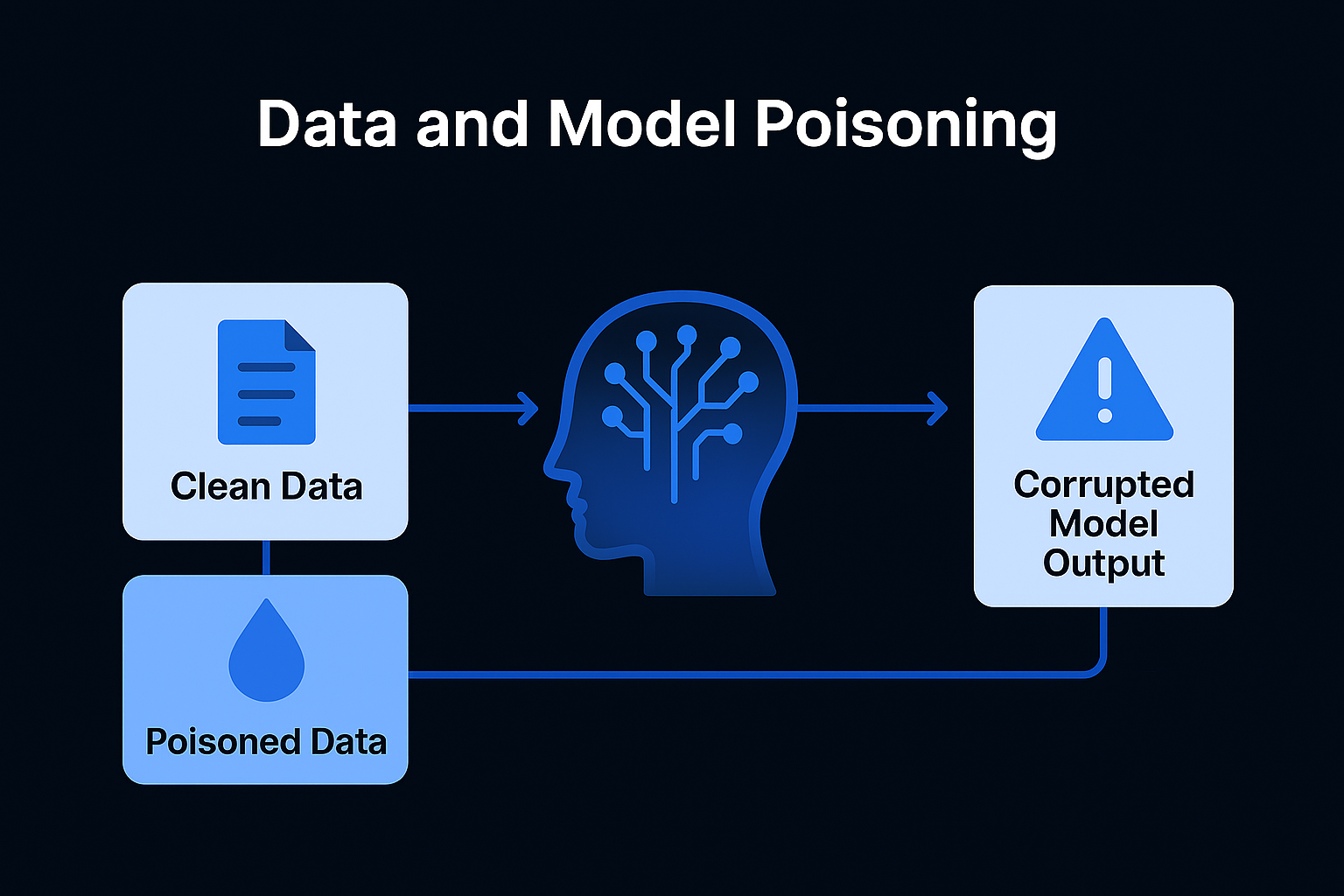
As organizations shift toward fine-tuning their own models on proprietary data, LLM04: Data and Model Poisoning has moved to the forefront of the AI Security Framework. If the data used to teach your AI is compromised, the AI’s very "logic" becomes a weapon for the attacker.
Poisoning occurs when an attacker introduces malicious information into the training or fine-tuning phase of an AI model. This isn't about breaking the model; it's about re-programming it.
This involves injecting "bad" data into the training set.
This is more direct and often happens via the AI Supply Chain.
[Image: A diagram showing the "Clean Data" stream being contaminated by a "Poisoned Data" injector, leading to a "Corrupted Model Output."]
As we move toward autonomous AI agents that handle logistics and code generation, the stakes of poisoning have skyrocketed. An AI poisoned during training could be instructed to:
To protect your model's "mind," you must implement a rigorous verification process. In 2026, we call this AI Data Provenance.
You can no longer scrape the web blindly. Every piece of data used for fine-tuning must have a documented origin.
Before training begins, run your data through an anomaly detection layer.
A Golden Dataset is a hand-curated, 100% verified set of Q&As that represent the "ground truth" for your business.
Hire security experts to perform "trigger discovery." They use adversarial techniques to see if the model has any hidden "sleeper agents" that respond to specific, nonsensical prompts.
Defense LayerTechnical ActionImpact
Ingestion Data Provenance & Source Vetting Prevents external "bad actors" from entering the pipeline.
Pre-Processing Anomaly Detection & Scrubbing Removes statistical outliers that skew model logic.
Evaluation Golden Dataset Comparison Identifies if the model's "core values" have been shifted.
Post-Training Adversarial Red-Teaming Proactively searches for hidden triggers and backdoors.
In 2026, high-security sectors (Finance, Healthcare, Defense) use a Random Sampling Audit. For every 1,000 items added to a training set, a human expert must manually verify a random sample of 10. If even one item is found to be intentionally misleading or poisoned, the entire batch is quarantined.
Your AI is only as good as its education. If you allow poisoned data into your training pipeline, you aren't just building a flawed tool—you're building a liability. By focusing on Data Provenance and Golden Dataset Verification, you ensure your model remains a loyal asset.
Protecting your training integrity is a foundational part of the AI Security Framework. But once your model is "smart" and "clean," you still have to worry about how it talks to the outside world—which brings us to the risks of output handling.




