
January 11, 2026
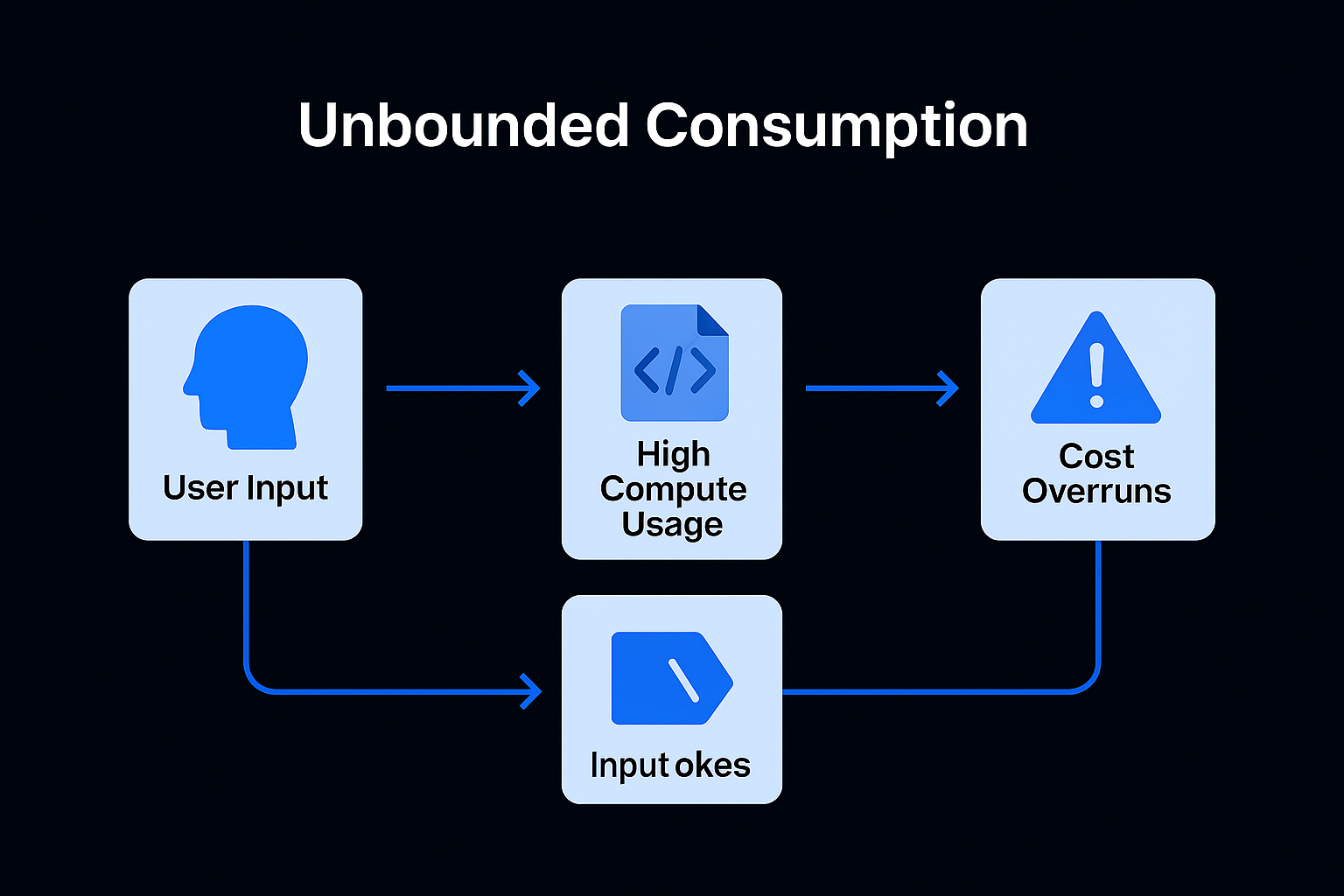
We have reached the final pillar of our AI Security Framework. While previous risks focused on what the AI says or how it is trained, LLM10: Unbounded Consumption is about the raw survival of your application.
In the world of 2026, tokens are the new currency. Unlike traditional software where a "Denial of Service" (DoS) attack might just crash a server, an attack on an LLM can result in a "Denial of Wallet" (DoW)—where an attacker doesn't just knock you offline, they bankrupt you in the process.
Traditional DoS attacks flood your network with traffic. AI-specific consumption attacks are much more surgical. They exploit the fact that processing a single complex prompt can cost $100\times$ more than a simple one.
Attackers craft "recursive" or "impossible" prompts that force models optimized for multi-step reasoning into an infinite loop.
Modern models (like Gemini 1.5 Pro) have context windows of 1M+ tokens.
If your AI is an agent that can call external APIs (like a weather or stock tool), an attacker can trick it into calling that tool 1,000 times in a single session, incurring costs on both your AI provider and your tool providers.
In 2026, treating "Availability" as a security boundary means treating tokens, compute, and execution time as protected resources.
Never allow an "unlimited" response.
max_tokens parameter in every API call. This prevents the model from "rambling" indefinitely during a hallucination or attack.Standard rate limiting (requests per minute) isn't enough for AI. You need Token-Based Rate Limiting.
For agentic workflows, you must put a "leash" on the AI's autonomy.
Why pay for the same answer twice?
Defense Layer Technical Control Primary Goal
Input Layer Length Validation & PII Scrubbing Prevents "Context Padding"
Orchestration Semantic Caching Reduces redundant API spend
Model Layer Max Token Caps / Model Cascading Prevents "Rambling" and DoW
Agent Layer Depth Limits & Timeouts Stops "Reasoning Loops"
Leading organizations no longer use their "smartest" (and most expensive) model for everything. They use a Cascade:
max_tokens on every single LLM API call?
Congratulations! You’ve navigated the full 2026 AI Security Framework. From preventing Prompt Injection to stopping Unbounded Consumption, you now have the blueprint to build AI that is not just powerful, but resilient.
Security in the AI era isn't a one-time setup—it's a continuous process of Monitoring, Red-Teaming, and Refining.




